

🎄 주제
- Data Lake 소개
- Data Lake 등장 배경
- Data Lake 구축방식 선정
🎄 자료 & 우리의 Data Lake 와 연결
0. 개요
- Data Lake 라는 용어는 ‘데이터 웨어하우스’ 솔루션 업체로부터 나온 것이 아니고, ‘BI(Business Intelligence )’ 솔루션 업체 관계자가 자신의 블로그에서 처음 했던 말
- 단어의 탄생은 BI 솔루션의 특성 상 Data Lake 는 “데이터 활용” 과 뗄 수 없음
1. 데이터 분석 플랫폼 발전 과정

기간 별 데이터 플랫폼 주요 키워드
- 1990 : ERP
- 2000 : 각 부서 나뉜 시스템을 연계하기 위한 Data Warehouse
- 2010 : Big-Data → Data Scientist
- 2020 : 데이터 SelfService, Data Lake
2006년 Hadoop 의 등장으로 3V(Volumn : 크기, Velocity : 속도, Varienty : 유형) 을 다룰 수 있게됨
- 이와 같이 2010년대에는 Data Scientist 라는 영역이 상기게 됨
- 2010년 특정 업무를 중심으로 구축한 빅데이터 시스템을 Data Puddle(데이터 웅덩이), Data Pond(데이터 연못이라고 부름 → 데이터 연못 간 문제가 발생함
- 데이터 연못 간에는 데이터가 공유되지 못하는 단절(Silo)이 발생함
- ‘데이터 특권화’ : 일반사용자는 데이터를 사용하지 못하고, Data Scientist 만 활용할 수 있는 데이터가 됨. ( Data Scientist 가 특정 권한을 이야기하는 것일뿐 직책을 이야기하는 것은 아님)
Silo 와 데이터 특권화 문제를 해결하려는 2020년 방식 → Data Lake
- 특정 사용자와 부서가 아닌 ‘Citizen 분석가’ 라고 불리는 일반사용자에게 공유하고자 하는 것이 목적
Data Lake 의 주요 특징
- Raw 데이터 형태로 공유하여 최대한 분석의 자유를 보장
- Citizen 분석가가 “Self-Service 분석” 이 가능하도록 보장해야함
- 쉽게 데이터를 찾을 수 있어야하고,
- 데이터의 Context(배경지식) 을 제공할 수 있어야하고,
- 다양한 도구를 통해 데이터 전처리 및 분석이 가능해야함
- 피처 저장소
- 셀프 BI
- A/B 테스트
- 딥/머신 러닝
IT 시스템 담당자의 개발이나 지원 없이, 자유롭고 편리하게 빅데이터를 분석하고, 그 숨겨진 의미(insight)를 발굴하여 자신의 업무에 적용함으로써, 전사적인 비즈니스 혁신을 유도하는 것, 이것을 Data Democratization (데이터 민주화) 라고 하며, Data Lake 를 통해 데이터 민주화를 시작하는 시대에 있음 — 현재
2. Data Lake 구축 방식 선정

- 자신의 회사의 상황과 시장 상황을 분석
- 선택 가능한 옵션이 무엇이 있는지 검토
우리 회사 데이터를 Data Lake 구축방식과 비교해보자 ( 온프레미스, 클라우드, 하이브리드)
- 자신의 회사의 상황과 시장 상황을 분석
- 리소스 소요 번동 폭
- 수집은 차단 이슈 및 추적 방지 문제로 빠르게 구축이 가능한 클라우드가 적절함
- 비즈니스 혹은 데이터 수집이 늘어났을 때 저장소도 유연하게 늘어야하기 때문에 클라우드가 적절함
- 데이터 민감도 : 퍼그샵, 스토어링크의 회원과 기업 정보, 고객 정보는 민감 데이터가 포함될 수 있음
- 민감한 정보만 따로 관리하는 데이터 서버를 온프레미스에 두는 것도 고려해볼 수 있음
- 실시간 처리 필요성 : 현재 스토어링크, 퍼그샵이 실시간 처리를 진행하고 있으며 클라우드를 통해 진행해도 무리없을 정도의 처리량
- Biz/업무의 특수성 : 네이버, 쿠팡, Qoo10JP 등 국내외 쇼핑몰 데이터 수집 및 분석
- 적재는 온프레미스, 클라우드 모두 가능
- 보유 리소스(인력/비용) 수준 : 회사에 온프레미스를 설치하고 관리할 수 있는 공간이 충분하지 않음
- 공간이 마련되더라도, 온습도, 정전방지, 소음, 주변 관리를 위한 자원이 필요함
- 데이터 센터 위협, 취약성 및 위험 평가 : https://learn.microsoft.com/ko-kr/compliance/assurance/assurance-threat-vulnerability-risk-assessment ********
3. Data Lake 추진 로드맵 수립
🪄 단계별 추진 계획, 즉 로드맵을 수립하는 이유
- 경영진의 ‘스폰서십(Sponsorship)’ 을 받기 위해
- 전략/재무 부서의 사업 예산 승인을 위해
- 사내 구성원과의 Communication 등을 위해 반드시 필요한 단계
“ IT 부서는 Cost Center 로써 Profit Center 대비 조직 내 입지 약화 등 사업 추진에 어려움이 존재합니다 ”
- 처음부터 기술적인 디테일에 지나치게 매몰되지 않고, 사용자 서비스 관점의 단계별 목표를 수립하는 것이 바람직합니다.
- 지속적인 예산 확보와 경영진의 스폰서십을 받기 위해서 기업의 비즈니스 가치(Value) 에 기여할 수 있는 과제를 선정, 가시화 하여 추진하는 것이 필요합니다.
- 🪄 비즈니스 가치와 연결되는지 가시화는 데이터팀 업무 에서 확인할 수 있다.
“비즈니스 성과 or 비용 절감 효과” 를 기대할 수 있어야함
1. 데이터 팀으로써의 로드맵 & 개인으로써의 로드맵
2. “비즈니스 성과 or 비용 절감 효과” 를 기대할 수 있어야함 - 우리의 작업과 연결해볼 수 있을까
개인으로의 로드맵
- Add-on 데이터 수집 파이프라인 정리
- 스케일링 기반의 ETL 처리
- 셀프 BI 를 통해 사용자 서비스 구축
4. Data Lake 아키텍처 설계
- 아키텍처는 레이어를 나누고 기능을 정의하고 필요한 기술을 정의하고 세부 구현방안을 설계해야함
- 가장 효과적인 방법은 “사용자 서비스 시나리오”를 빠짐없이 정의하고, 이에 기반하여 기능을 도축하고 Data Pipeline 을 설계하여 시나리오상의 요구사항을 모두 충족시킬 수 있는지 확인하는 것입니다.
- → (승찬) 누구나 할 수 있는 이야기처럼 느껴짐. 데이터 레이크라서 특별한 점이 아니며, 데이터 레이크는 자율성을 보장해야한다고 했는데 특정 사용자 서비스 시나리오로만 한정한다면 데이터웨어하우스와 다르지 않을 수도 있을 것 같음
특히, Data Lake 사용자는 Data Scientist 뿐만 아니라 Citizen 분석가를 타깃으로 하므로, 반드시 이들 관점에서 설계해야 합니다.
- IT 솔루션을 도입한다면 요구사항, 구현 기간과 비용을 단축시킬 수 있음
- 그러나, 굳이 필요하지 않은 기능을 사야하거나 라이선스 비용이 비싸며 특정 솔루션에 종속될 수 있음
- 빅데이터 기반 Open-Source 솔루션을 도입한다면 커스터마이징과 운영 비용은 줄일 수 있음
- 전문성을 보유한 인력을 확보하기 어렵고, 오픈소스 도입으로 인한 아키텍처의 복잡성 증가가 운영에 어려움을 줄 수 있음
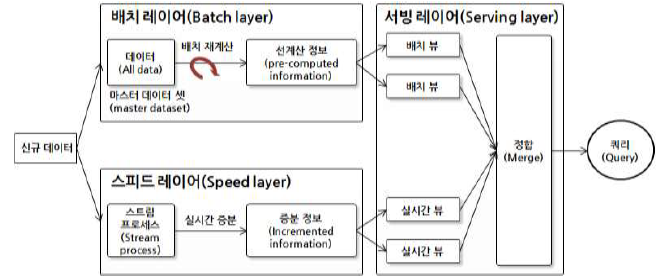
참고할 Data Lake 아키텍처 : 카파 아키텍처 vs 람다 아키텍처 → 3장에서 더 자세하게 다룸


- 카파 아키텍처 : 메시지 아키텍처 기반의 실시간 처리 + 배치 처리를 합쳐서
- 람다 아키텍처 : 배치와 실시간 아키텍처를 분리
Data Lake 아키텍처 Layer
- 데이터 수집 Layer - 데이터 수집 프로세스와 관련된 영역
- 관계형 데이터베이스 테이블, CSV 파일 등 정형 데이터
- IoT 로그, JSON 등의 반정형 데이터
- 영상 및 음성 비정형 데이터
- 데이터 적재 Layer - 데이터 가공(아래 세부 영역으로 데이터들이 이동함)
- 임시 데이터 영역 - 데이터 적합성 검토, 보안 데이터 여부 체크, 비식별화/마스킹 처리
- 원천 데이터 영역 - Data Catalog 를 통해 Raw Data 서비스를 제공
- 작업 데이터 영역 - 사용자가 직접 필요한 데이터 가공 혹은 새로운 데이터를 생성
- 가공 데이터 영역 - 다른 사용자에게 제공하기 위해 작업 데이터 영역의 데이터를 Data Catalog 에 배포
- 데이터 제공 Layer - 사용자에게 데이터를 어떻게 제공할 것인지 기술적인 방식이 고려되는 영역
- 예시) 저장소 직접 연결 후 다운로드를 할 수 있는 기술
- 예시) 대화형 쿼리 → REST API 를 통해 다운로드를 할 수 있는 기술
- 데이터 서비스 Layer - 사용자들이 데이터를 어떻게하면 쉽게 찾고 분석할 수 있는지 제공하는 영역
- 대표적으로 Data Catalog 서비스 - Data Catalog에는 매우 다양한 기술들이 포함될 수 있음
- 필요한 데이터 검색
- 전처리/분석 기능
- 정확한 파일명, 테이블 명이 아닌 비즈니스 용어를 통해 검색
- 데이터 계보(Data Lineage) : 샘플
- 실제 샘플을 보여주기
- 데이터 프로파일링 - 결과 값 분포
- 데이터 활용되고 있는지 보여주기
- 사용자들의 피드백을 받아 전사 사용자와 공유하는 기능
Data Catalog 는 단순히 메타데이터를 제공하는 것 이외에 인터넷 포털처럼 사용자들간의 커뮤니케이션이 활발하게 진행될 수 있는 상태를 제공해야함 - Data Portal 이라고도 불림
우리가 부족한 영역 생각해보기
5. Data Lake 플랫폼 활용도 향상
- 데이터레이크는 철저하게 사용자 관점의 서비스 구성이 필요합니다.
- 사용자는 자신에게 익숙한 용어로 필요한 데이터를 검색 및 찾을 수 있어야하고, 데이터에 대한 Context 이해 및 해당 데이터 소유자에게 궁금한 점을 문의할 수 있어야합니다.
- 전사적으로 “Data Lake 중심 문화 조성” 도 필요합니다.
- 각 부서별 데이터를 Data Lake 로 통합하는 방향 - 🪄 우리에게 알맞은 방향인지는 생각해봐야함
- 처음에는 익숙하지 않고, 명확한 기준 데이터 부재, 데이터 오류 등으로 불편할 수도 있지만 시간이 지날수록 데이터의 정합성도 높아지고 기존에 비해 유연함과 편리함을 느끼면서 활성화 될 수 있을 것입니다.
- Gamification (게임화) 의 도입 - “가시화의 힘”
- 사용자의 활용 트렌드를 가시화하여 투명하게 전사에 공유하는 것
- Data Lake 활용도를 점수화하여 보여주는 것
- cf. 애자일 - 정보 방열기

6. Data Lake 거버넌스
- Data Lake 데이터의 품질은 엄격하게 관리되어야합니다.
- 데이터 프로파일링을 통해 데이터 누락, 오류, 중복이 발생하지 않아야하고,
- 원인 확인 및 조치까지 자동화가 이루여져야 합니다.
- 보안 관리도 중요합니다.
7. Data Lake 추진 조직
- 현업 비즈니스 부서에서는 ‘데이터 오너’ 오너 데이터 비즈니스 의미를 Data Catalog 에 반영해야 하며, 일반 사용자 Citizen 분석가의 역할을 수행해야합니다.

🎄 참고자료


Share article